Members that participated (10 crackers/ 1 support)
s3in!c
golem445
hops
blazer
gearjunkie
winxp5421
AMD
cvsi
pdo
Waffle
Usasoft (support)
Peak computing power (25-30 standardized to 4090)
Before the contest
The test hashes gave us a gleam of what the potential hash data would look like. After successfully cracking all the test hashes, we noticed very heavy use of UTF-8 encoded characters. We ensured we had adequate tooling to handle UTF-8 strings, detect character sets and expanded toolkits to leverage translation API for batch language translations. We also created tooling to parse the yaml data into usable and more manipulable formats.
During the contest
Our very first issue we encountered was the {ssha512} hashes, since hashcat outputs these as {SSHA512} we had to quickly update our system to perform some translations to handle the alternate case.
We identified the timestamp pattern early on and those were used to quickly gain cracks on bcrypt. The metadata did throw us off a little bit initially as we were not totally sure how it was incorporated into the plaintext. Early on we were unsure whether they gave us a hint or whether the plaintext contained a portion or manipulated form of the metadata. Due to the insanely slow hashrate of bcrypt and sha512crypt sha256crypt it took our team quite some time to gather enough samples to deduce that the plaintext patterns were distributed across all the algorithms evenly.
We were quite perplexed 12 hours into the contest by how other teams were able to consistently yield cracks for bcrypt while it appeared we were not really traveling anywhere. Once the plains were analyzed we identified some movie lines. We initially started off with Star Wars movie lines, then progressed to Star Trek movie lines, these were the following critical patterns identified.
Lines containing 2,3,4 words were extracted based on the word boundaries from movie scripts/subtitle files, then divided into various lengths for attacks
Len13?s (where s = !@$%)
Len12?d?s (where s=!@$%)
Len14+ suffix 1
We initially were not totally sure whether all the symbols were used or what the specific attributes were, so there were wasted resources used to check these. However, as the runs progressed, we were able to reduce the keyspace by improving our parameters, such as using only certain suffix patterns with certain lengths.
Once we knew the correlation between the hash sets, it was merely a game of attacking the fastest algorithm MD5, then filtering the attacks through all the algorithms to maximize points. Since we used a much larger repertoire of movie lines and corpuses on the faster hash types, we used the obligatory ChatGPT to identify the origin of the phrases. This involved converting our cracks to base words and asking where the phrases came from. Once all the sources were identified, we manually gathered all the movie lines/srt files and processed them as described above. Very large tasks were spawned to cover exactly those patterns, which gave us consistent cracks throughout the contest. The list below were the films we identified.
This was the movie list we used
2001 A Space Odyssey
Alien series
Army of Darkness
Battlestar Galactica
Blade Runner
Close Encounters of the Third Kind
Contact
Dune
Event Horizon
Ex Machina
Firefly
Ground control
Guardians of the Galaxy
I, Robot
Inception
Interview with the Vampire
Mad Max
Minority Report
RoboCop
Star Trek
Star Wars
The Day the Earth Stood Still
The Expanse
The Fifth Element
The Galaxy Quest
The Hitchhiker's Guide to the Galaxy
The Matrix Trilogy
The Terminator
The Thing
The War of the Worlds
Tron
Since many plain texts were recovered using this method, we will add some additional information. We suspected there was a parsing defect (it was disclosed in the discussion afterward that delimiting on punctuation characters was used, which is why we noticed this obscure behavior).
When parsing our datasets, we were delimiting only on space as opposed to a sliding window method to ensure full word boundaries sentences were created, e.g. “something was here” instead of “omething was here”. However, we noticed in our cracks that we had phrases that were not “word bounded”, they appeared like this
“t go there today”
“ve got to be here”
For some reason, it did not occur to us that the phrases could be delimited on punctuation. Instead, we took a different approach and emulated this behavior. We simply took our existing phrase lists and prefixed d/t/s/m or ve/re while maintaining length constraints, this also gave us very good results. It was important to note that since we were dealing with long lengths, it was important to turn off “-O” when used with SHA512crypt sha256crypt due to the length 15 limitation.
We crafted some additional tooling during the contest to visualize and query the datasets with standard SQL like queries (yay to SQLite). All our new and existing plaintext cracks along with all the metadata were associated and synced constantly. This tooling played a pivotal role not only in creating -a 9 association attacks, but also in helping us identify patterns and create hash subsets. Some of these patterns included.
#3&4%# only applied to Telecom users
Russian users with russian words with suffix ‘1’
Icelandic phrases for users with Icelandic names
Ghosting users with the hinted passwords
Company names with word suffix
Saleswords + prefix/suffix rules for sales team
Being able to cut down the salt list for the slow algorithms meant we did not actually need lots of computing resources, we would strategically target subsets of hashes when we suspected a pattern. It was noticed that lots of effort was put in by Korelogic in generating the dataset. We noticed that Japanese users had Japanese passwords, usually users with UTF-8 encoded names used UTF-8 encoded passwords, even the area the user was from determined the password such as Indian users having Hindi passwords.
We were able to decode all the hints. However, at times I think we read too deep into these, and they almost sent us down a rabbit hole, throwing us off.
The workflow below roughly describes the process used. When large attacks were crafted and dispatched, users who felt like joining would participate, while others continued to run other attacks and discover new patterns for analysis. We also ran translations of the base words through various languages and tested numerous times to see if we could spot new languages.
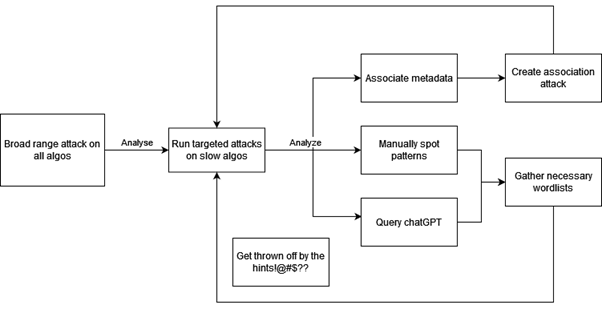
We did not have any designated role, the team just played off on everyone's strengths. An example is that we initially found many of the word phrases via a large generic reddit comments wordlist which was quickly distributed among us, this then progressed to movies, from there on we identified the subset of movies. Due to the short phrases, it was not easy to determine the origin early on as they could have come from anywhere, though we were eventually able to piece things together. We worked collectively in gathering the various resources and once ready these resources and tasks were distributed via our job management system and those who opted to would join in. During this entire time various scripts/tools/ideas/automation/platform updates were made on-the-fly and contributed to ensure we were working with optimal resources and efficiently.
Things we missed
We were able to partially solve the prod/dev [separator] hint. We found the following separators (-_| %20). Sadly, we tested the other URL encodes in upper hex format %2F instead of %2f, so we missed numerous cracks here.
We did spend some time on the CRC hint and parsed the CRC book, scoured the web for chemical compounds. Wrote scripts to generate carbon chains. While we did get a few cracks, it did not appear that significant, or maybe we were not able to find them.
We did not use a large repository of books, it appears that our movie list gave us enough work to compute through and most likely had overlap with books.
We did see some streets/roads early on but forgot to pursue this further.
We noticed some mathematical formulas as passwords, though did not look took deep into this
We had a member suggest the use of a dictionary labeled as ‘polkski_dict’ (which appeared to contain a random assortment of things) very early on. This was far too big to test across the tougher algorithms, we put it aside and forgot about it until near the end where we were able to cut down the contents and found it to be decent in producing founds, we were not able to fully exhaust this dictionary due to time limits.
Take-away
While a large number of compute resources certainly makes a difference, if you are simply throwing hashes and random lists/attacks at the situation and hoping for the best, more likely than not the outcome won't be desirable. Identifying patterns and sources then optimizing the attack parameters such as cutting down salts via attacking a subset of hashes or using a specific list set/rule helps dramatically, also ensuring the workload is able to saturate the compute cores is also critical.
All in all, our team as usual had very little sleep and a wonderful time solving the challenges and competing against the best teams. It was great to be able to use correlated data in hash cracking. We can only imagine the thought and effort involved in creating the challenges along with hints and finally wrapping it all up in a nice, well-run contest. Kudos to Korelogic.